Kan Zhu
Kan Zhu
Home
Publications
Awards
CV
Light
Dark
Automatic
Publications
Type
Conference paper
Date
2024
Keisuke Kamahori
,
Yile Gu
,
Kan Zhu
,
Baris Kasikci
October, 2024
ICLR Workshop 2024
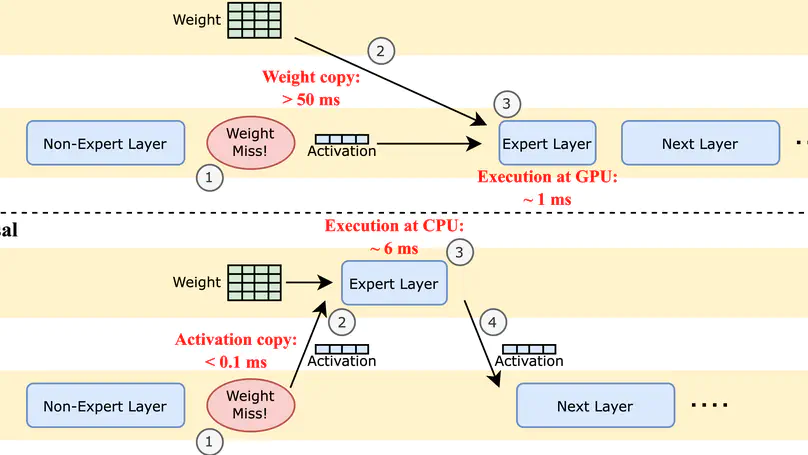
Fiddler: CPU-GPU Orchestration for Fast Inference of Mixture-of-Experts Models.
We propose Fiddler, a resource-efficient inference engine with CPU-GPU orchestration for MoE models.
PDF
Code
Kan Zhu
,
Yilong Zhao
,
Yufei Gao
,
Peter Braun
,
Tanvir Ahmed Khan
,
Heiner Litz
,
Baris Kasikci
,
Shuwen Deng
October, 2024
HPCA 2025
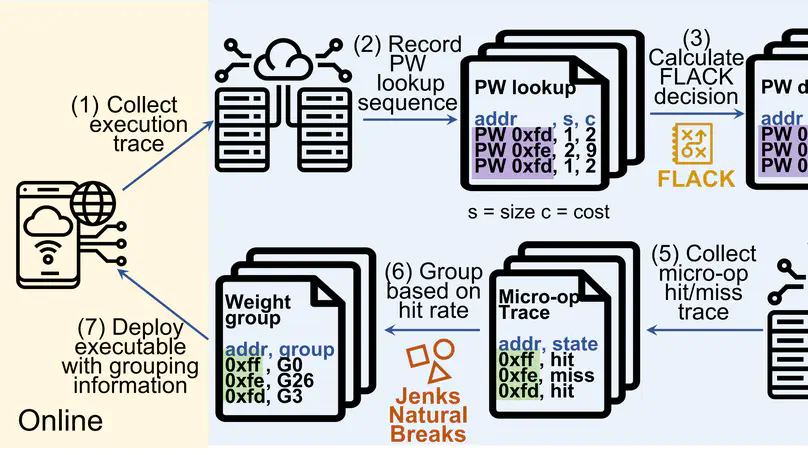
From Optimal to Practical: Efficient Micro-op Cache Replacement Policies for Data Center Applications
Understand the limitations of state-of-the-art replacement policy and the uniqueness of micro-op cache.
Proposed and evaluated counter-based, profile-guided replacement policy
Yilong Zhao
,
Chien-Yu Lin
,
Kan Zhu
,
Zihao Ye
,
Lequn Chen
,
Size Zheng
,
Luis Ceze
,
Arvind Krishnamurthy
,
Tianqi Chen
,
Baris Kasikci
October, 2024
MLSys 2024
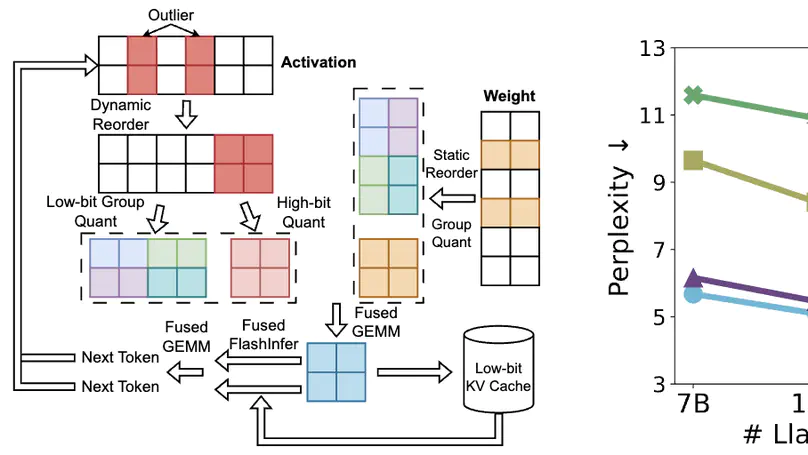
Atom: Low-bit Quantization for Efficient and Accurate LLM Serving
Use activation and weight low-bit quantization to improve throughput.
PDF
Code
Jiaming Tang
,
Yilong Zhao
,
Kan Zhu
,
Guangxuan Xiao
,
Baris Kasikci
,
Song Han
October, 2024
ICML 2024
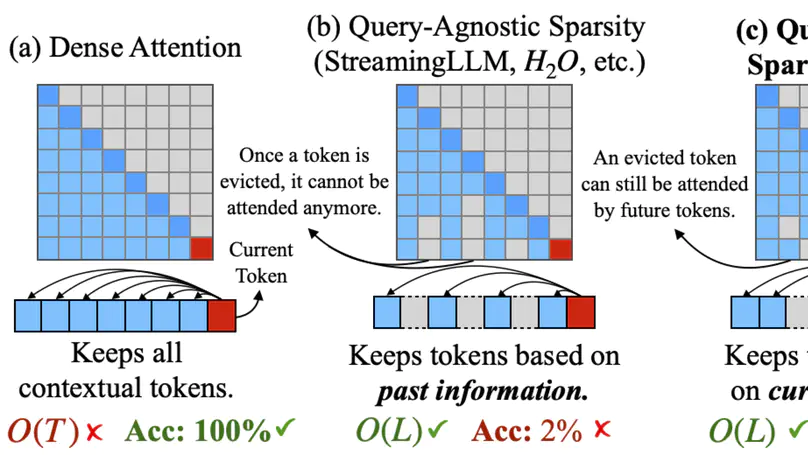
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Identified the sparsity in the attention mechanism of long-context LLMs
Dynamically choose critical tokens based on the query
PDF
Code
Kan Zhu
,
Yilong Zhao
,
Liangyu Zhao
,
Gefei Zuo
,
Yile Gu
,
Dedong Xie
,
Yufei Gao
,
Qinyu Xu
,
Tian Tang
,
Zihao Ye
,
Keisuke Kamahori
,
Chien-Yu Lin
,
Stephanie Wang
,
Arvind Krishnamurthy
,
Baris Kasikci
October, 2024
Arxiv 2024
NanoFlow: Towards Optimal Large Language Model Serving Throughput
Identified the underutilization of resources within a single device in existing serving systems due to sequentially executing operations with various resource requirements
Overlapping the utilization of different resources within a single device through operation co-scheduling for higher resource utilization
PDF
Code
Cite
×